想象一下,你是一位站在一座巨大、无序的城市面前的侦探。你的任务是搞懂这座城市的运作方式——不仅仅是宏观的规划,还要了解每一位市民的生活:他们做什么工作,和谁交谈,是健康还是生病。现在,再想象一下,每位市民都留下了一本详尽的日记,但全是用一种复杂的、你完全不懂的外星语写成的。
这,就是“单细胞测序”时代生物学家的日常。
几十年来,科学家研究组织器官的方式,就像做一杯冰沙。他们把组织磨碎,得到一个总体的“风味”——比如,这个样本是 20%的苹果加 80%的香蕉——但却失去了每一颗独立水果的精美细节。而“单细胞测序”技术改变了一切。它让科学家能放大到极致,去分析一个组织里每一个细胞独特的基因活动。我们突然之间,拥有了数百万“市民”的日记。
但问题也随之而来:堆积如山的数据是如此庞大和复杂,以至于解读它需要一位“翻译专家”——一位精通 Python 或 R 等编程语言的生物信息学家。这就形成了一个巨大的瓶颈。生物学家,那些最懂“问题”在哪的专家,不得不把自己宝贵的数据交给程序员,那些最懂“工具”的专家,然后焦急地等待“翻译”结果。我们与自身生命奥秘的对话,因此变得缓慢、笨拙且充满隔阂。
直到现在。如果……我们能直接和数据“对话”呢?
在维也纳的 CeMM 分子医学研究中心,由 Christoph Bock 博士领导的一支团队,决心要打破这道语言壁垒。他们构建了一个人工智能,并给它起了一个绝妙的名字:CellWhisperer(细胞低语者)。这个 AI,让我们得以一窥科学研究的未来。它不仅是一个新工具,更是一种与生命本身进行“交谈”的全新方式。
核心使命:为生物学打造一台“万能翻译机”
研究人员深知,简单的“翻译”数据是远远不够的。他们需要搭建一座桥梁,连接两个截然不同的世界:一个是充满数字和代码的基因活动世界,另一个是人类直观、充满描述的语言世界。
为此,他们设计了一个巧妙的、由两部分组成的 AI 系统。
第一部分:细胞世界的“罗塞塔石碑”
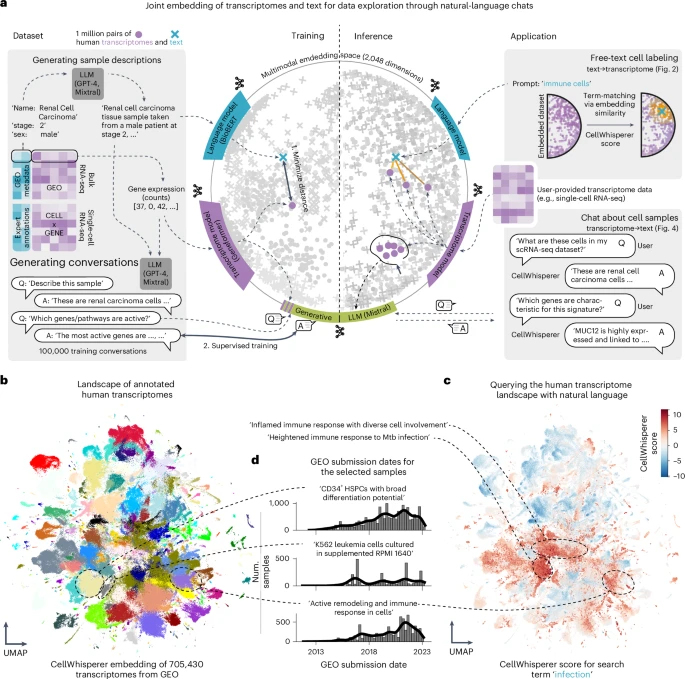
首先,他们得教会 AI 同时理解“基因语言”和“人类语言”。你可以把这个过程想象成是在打造一块生物学领域的“罗塞塔石碑”。他们从公共数据库中,收集了超过一百万份细胞的基因图谱。每一份图谱,都像一个由数千个基因组成的独特“条形码”,清晰地展示了哪些基因被激活、哪些被关闭,从而定义了这个细胞的身份和功能。
接下来,就是最精彩的部分。他们将这一百万个基因条形码,与一段人类语言的描述一一配对。例如,某个特定的基因条形码,会和一个文本标签“来自一位男性患者的肾癌细胞”关联起来。
通过一种名为“对比学习”的强大 AI 技术(它的魔法和 DALL-E 这类文生图 AI 背后的原理相似),他们训练模型创造了一个共享的“意义地图”。在这个神奇的空间里,代表“肾癌细胞”的基因条形码,就紧挨着描述它的那团文字云。本质上,他们教会了 AI 生命的词汇表,将抽象的数据与具体的含义联系了起来。系统的这第一部分,被称为**“嵌入模型”**——它是整个系统的基石翻译官。
第二部分:专家级的“对话者”
有了翻译官还不够,你还需要一个能主持对话的人。为此,团队转向了大型语言模型(LLM),也就是 ChatGPT 背后的那种技术。他们选择了一个强大的开源模型——Mistral 7B。
但他们并没有让这个 LLM 仅仅去“阅读”生物学教科书,而是赋予了它一项超能力:随时查阅那块“细胞世界的罗塞塔石碑”。当用户与 CellWhisperer 互动时,他们提出的问题,会与他们正在观察的细胞的真实基因数据相结合。
这才是真正的游戏规则改变者。你不再是问一个通用的 AI:“T 细胞有什么特征?”。你可以直接在屏幕上圈出你自己实验里的一群特定细胞,然后问:“就是这儿,这些细胞到底是什么?”
LLM 接收到你的问题后,会立刻在它的“罗塞塔石碑”地图上,查找你所选细胞的独特基因条形码,并根据它的发现,生成一个答案。它可能会这样回答你:“你选择的细胞似乎是 CD16+自然杀伤细胞,它们在先天免疫反应中扮演着至关重要的角色。”
这是一个将你的真实数据与 AI 庞大的生物学知识库无缝融合的过程。
从科幻到现实:一个友好的聊天框
那么,它实际用起来效果如何?结果令人惊叹。
Bock 的实验室将 CellWhisperer 直接集成到一个广受欢迎的可视化分析工具 CELLxGENE 中。现在,复杂的菜单和一行行的代码不见了,取而代之的是一个简单的聊天框。
在一项测试中,研究人员探索了一个绘制人体器官的庞大数据集。他们输入了一个简单的指令:“给我看看有免疫功能的结构细胞。” 这是一个非常精妙的生物学问题,它要求找到那些构成身体“脚手架”(如成纤维细胞)但同时又扮演着免疫系统“士兵”角色的细胞。
瞬间,屏幕上的可视化地图亮了起来,精准地高亮了特定的细胞群。当他们放大并让聊天框描述这些细胞时,AI 生成了详尽而准确的总结,甚至指出了参与其双重功能的关键基因。
在另一项更惊人的演示中,他们给 CellWhisperer 输入了早期人类胚胎发育的数据。为了找到那些最终将发育成心脏的细胞,他们不需要输入一长串复杂的标记基因列表,只用了一个词:“心脏”。CellWhisperer 不仅准确地识别出了正在萌芽的心脏细胞,甚至还帮助发现了一些这个过程中潜在的新标记基因——这些发现在后续的科学文献核对中得到了证实。
也许最能说明问题的,是它与传统分析方法的一场对决。为了解答一个关于“发炎结肠组织中的干细胞”的问题,一位训练有素的生物信息学家,必须编写400 行自定义 Python 代码,并调用五个独立的软件工具。而借助 CellWhisperer,一位生物学家通过几次简单的聊天互动,在几分钟内就得出了相同的结论。
所以呢?AI 科研助理的黎明
CellWhisperer 的意义,远不止是节省时间,它代表了科学研究方式的一次根本性转变。
- 它实现了数据的“平权”:它将分析的权力,直接交还给了最懂生物学问题的科学家手中,不再需要“翻译”的等待。这极大地解放了创造力,加速了“提出假说-验证-发现”的科学循环。
- 它鼓励了探索精神:当提出一个问题的门槛,从“编写 100 行代码”降低到“输入一句话”时,科学家们便可以更自由地去追随自己的好奇心。他们能用更直观的方式去“戳一戳”自己的数据,验证那些过去因为太耗时而不敢尝试的灵感。
- 它是一个更宏大未来的开端:这仅仅是一个“概念验证”,它预示着一个 AI 将成为实验室里真正合作者的未来。想象一下,未来的 AI 助理能够同时分析来自显微镜、基因测序仪和临床试验的数据,然后用平实的语言与研究人员讨论它们的发现。
当然,其创造者也明确指出,这目前是一个用于探索和产生假说的工具。和所有 LLM 一样,它也可能犯错,所有关键的发现都应通过传统方法进行验证。但作为一张引领我们航行在生物数据浩瀚海洋中的“指南针”,它无疑是革命性的。
几个世纪以来,我们一直在从外向内地研究细胞。而现在,我们第一次开始学习如何去倾听细胞内在的声音。有了 CellWhisperer,看来,细胞终于准备好开口说话了。